毎日 通常購入しなくては使用できないソフトウエアを無料で提供します!

PDF Text OCR Xtractor 3.2.2.20< のgiveaway は 2024年9月5日

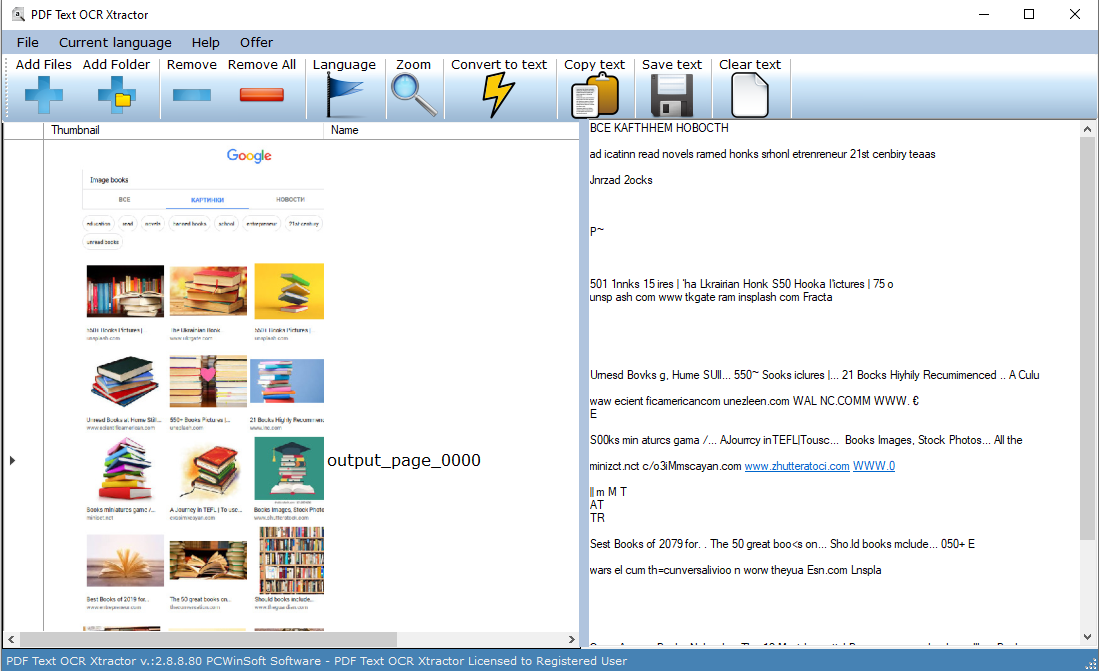
PDF Text OCR Xtractor は、PDF や、PNG、JPG、BMP、TIFF などのあらゆる種類の一般的な画像形式からテキストを抽出するのに最適です。 PDF テキスト OCR Xtractor は、Tesseract OCR テクノロジーを使用しています。 Tesseract は、おそらく最も強力で高度な OCR ソフトウェアです。その理由は次のとおりです。まず、少し歴史を説明します。 1994 年に HP によって開発されましたが、すぐに HP はオープンソース開発用の Apache ライセンスの下でリリースしました。 2006 年、Google がプロジェクトを引き継ぎ、Tesseract に取り組む開発者を後援しました。 Tesseract は、ディープ ラーニングを使用して画像 (BMP、PNG、JPEG、TIFF など) および PDF ファイルからテキストを抽出する最も強力な OCR エンジンになりました。 PDF Text OCR Xtractor は 20 以上の異なる言語をサポートし、ソース ファイル/画像を分析する前に、平滑化や DPI 調整、コントラストの増加、その他の便利なトリックなどのカスタム処理パラメーターをソース ファイル/画像に設定できます。 PDF Text OCR Xtractor は精度が高く、画像や PDF を編集可能な検索可能なテキストに変換します。画像からテキストへの変換は迅速です。主な機能: 1. 利用可能な最高の OCR テクノロジの使用。 2. 20 以上の異なる言語のサポート。 3. 難しいドキュメントの精度を高める便利な画像変換。追加機能: 1. 最も安価な Tesseract エンジンのグラフィカル ユーザー インターフェイスを見つけることができます。 2. PDF および PNG、JPG、BMP などのすべての一般的な画像形式のサポート。
The current text is the result of machine translation. You can help us improve it.
必要なシステム:
Windows 7/ 8.1/ 10/ 11 (x32/x64)
出版社:
PCWinSoftホームページ:
https://www.pcwinsoft.com/pdf-to-text.aspファイルサイズ:
103 MB
Licence details:
Lifetime
価格:
$29.90
コメント PDF Text OCR Xtractor 3.2.2.20
Please add a comment explaining the reason behind your vote.
Only English is supported.
Save | Cancel
Looks fine, but my language is not supported and the results with it are really poor. When I tried to switch to other language (more similar to mine then the English), it didn´t work. Trying to switch, I get dialog window "Language not installed. Do you want to install it?" I answer "Yes" - an nothing happens (I tried this with a few languages, only French was switched, no other).
And even in English the results are far from perfect. Maybe a keeper (I have no OCR program license now and I need it rarely, so a free solution is fine), but far from the professional solution (ABBYY) I have used in the past.
Save | Cancel
Only english.Where is language pack ?
Save | Cancel